




En el artículo anterior, vimos cómo instalar y configurar Git en tu equipo y cómo crear tu primer repositorio. En este artículo vamos a ver cómo añadir nuestros primeros archivos al mismo, cómo se realiza su versionado y revisaremos también su ciclo de vida.
En general, trabajarás con un repositorio local, que es el que tienes en tu ordenador, y un repositorio remoto, que puede estar en GitHub, GitLab, o donde sea. En este artículo comenzaremos directamente sobre tu repositorio local, dejando para futuros artículos la sincronización con repositorios remotos.
Qué pasa en tu repositorio local
En nuestro repositorio local, creado como vimos en el artículo anterior, tenemos tres depósitos o estados:
- Depósito o estado inicial. Este es el directorio de trabajo, donde se encuentran todos nuestros archivos, aquellos que editamos y modificamos.
- Depósito o estado intermedio. Un almacén o depósito llamado Index o Stage. Esto es una especie de memoria caché. Aquí vamos registrando todos nuestros cambios antes de guardarlos en el depósito final
- Depósito o estado final. Un depósito llamado HEAD donde se guarda lo último.
En el siguiente diagrama o esquema vemos todas las posibles transacciones que podemos realizar con un archivo dentro de nuestro repositorio local.
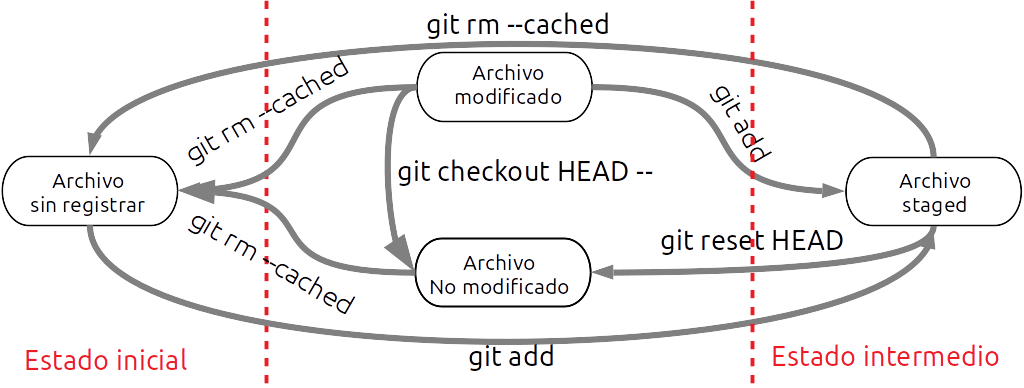
Así, cualquier archivo que modificamos, tenemos que transferirlo primero al depósito intermedio y, posteriormente, guardarlo.
Pongamos que creamos o copiamos un nuevo archivo en nuestro directorio de trabajo. Lo llamaremos mi_archivo. Este archivo, nada más crearlo, no está registrado en nuestro sistema de control de versiones. Sin embargo, está en el directorio de trabajo, en el depósito inicial. Para registrarlo y seguirle la pista (rastrear la traducción de track) ejecutaremos la siguiente orden:
git add mi_archivo
Al ejecutar este comando, nuestro archivo ha pasado del depósito inicial, o directorio de trabajo, al depósito intermedio, o Stage. Si queremos hacer marcha atrás y sacarlo de Stage, ejecutaremos la orden:
git reset mi_archivo
Todas estas operaciones siempre las estamos haciendo en nuestro repositorio local. Para que estos cambios se vean reflejados en el repositorio remoto hay que ir un paso mas allá. Debemos llevar nuestros archivos al depósito o estado final, al HEAD.
Para pasar del Stage al HEAD es necesario realizar un commit. Con esta acción todo lo que se encuentra en el Stage, y solo eso, pasa al depósito HEAD. Así, para realizar un commit, ejecutaremos la siguiente orden:
git commit -m "Mi primer commit"
Como te puedes imaginar, “Mi primer commit”, es un mensaje que añadimos para saber a qué se refiere ese commit. Por ejemplo, si has añadido una nueva característica, has corregido un error… o, simplemente, una falta ortográfica. En fin, lo que sea.
Igualmente, como sucedía en el caso anterior, también puedes devolver un archivo del estado final al estado intermedio. Para ello tan solo tenemos que ejecutar la orden:
git reset HEAD~
Ahora bien, ¿qué pasa una vez registrado mi_archivo, es decir, cuando se encuentra en el estado intermedio o Stage, y lo modificamos? Es decir, una vez registrado nuestro archivo le añadimos un nuevo apartado, o modificamos algo, o lo corregimos. En ese momento, es necesario realizar de nuevo un registro del cambio. Para ello, igual que al inicio de nuestro camino, ejecutaremos la orden:
git add mi_archivo
Ahora ya tenemos de nuevo nuestro archivo modificado registrado en el Stage. Si queremos que los cambios se vean reflejados para una próxima sincronización con el repositorio remoto, será necesario hacer un commit, como vimos en la primera parte.
git commit -m "Mi segundo commit. He modificado mi_archivo"
Evidentemente, hacer esto archivo por archivo puede ser muy tedioso. Aunque esto ya es totalmente opcional, depende de ti. Tú eres el que le da más o menos importancia a los cambios a considerar. Sin embargo, para registrar toda una serie de nuevos archivos o nuevas modificaciones en archivos, en lugar de ir uno por uno puedes ejecutar la siguiente orden:
git add .
Esta acción, no es exactamente la misma que git add. Por diferenciar,
∗ git add -A lo pasa todo al estado intermedio (Stage)
∗ git add . pasa todo lo nuevo y lo modificado al estado intermedio, pero no lo que se ha borrado.
∗ git add -u para al estado intermedio o stage todo lo que se ha modificado o borrado, pero no lo nuevo.
En ocasiones, te puede resultar interesante saltarte el depósito o estado intermedio, el stage. Si simplemente lo que estás haciendo es pasar de una a otra sin más, no tiene sentido utilizar este estado intermedio. En este caso, puedes realizar directamente el commit, añadiendo la opción -a. Así para realizar una confirmación o commit saltando el estado intermedio, tan solo deberás ejecutar la orden,
git commit -a -m "Saltandome el stage"
Conociendo el estado del repositorio
Inicialmente, cuando tienes pocos archivos, es posible, que conozcas en qué estado o situación se encuentra cada uno de ellos. Sin embargo, te puedo asegurar que a lo largo del proyecto, llegará el momento en que desconozcas la situación de todos los archivos. ¿Cómo puedes conocer la situación de tus archivos?. Para ello tan solo tienes que ejecutar la orden:
git status
Así por ejemplo, en un proyecto en el que estoy trabajando, al ejecutar esta orden, me arroja el siguiente resultado:
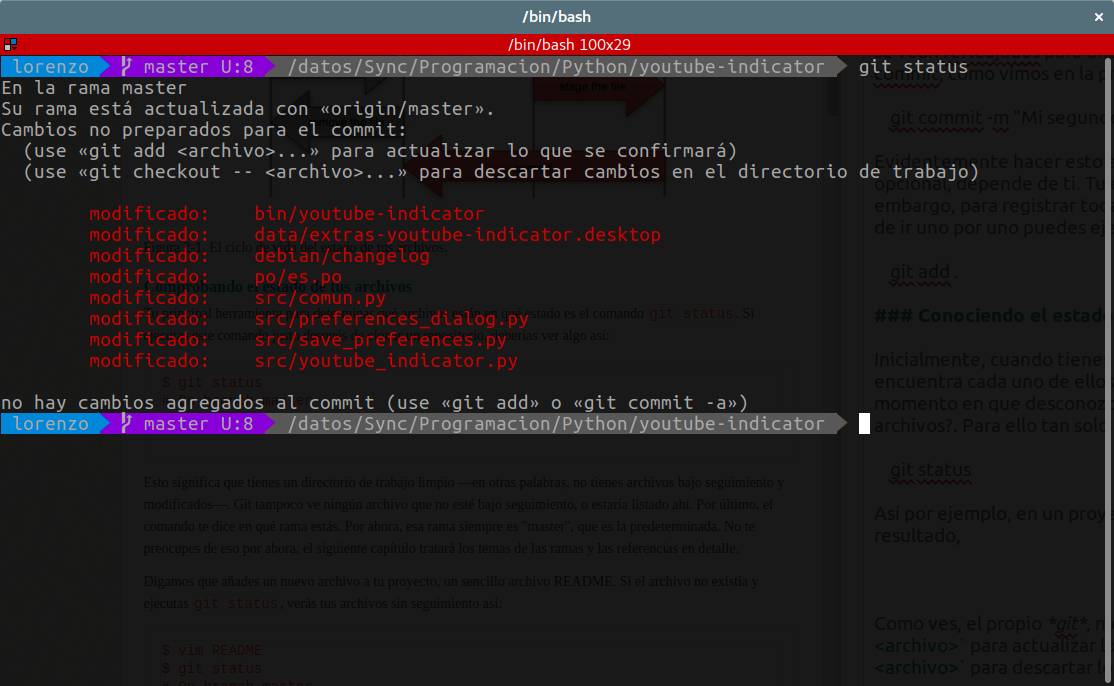
Como ves, el propio git, me indica las acciones que puedo tomar. O bien, me indica utilizar git add para actualizar los cambios que se confirmarán en el commit, o bien, utilizar git checkout -- para descartar los cambios que hicimos en el directorio.
Voy a confirmar todos los cambios, para lo que ejecutaré la orden:
git add .
Si ahora ejecuto git status, el resultado que arroja es el siguiente:
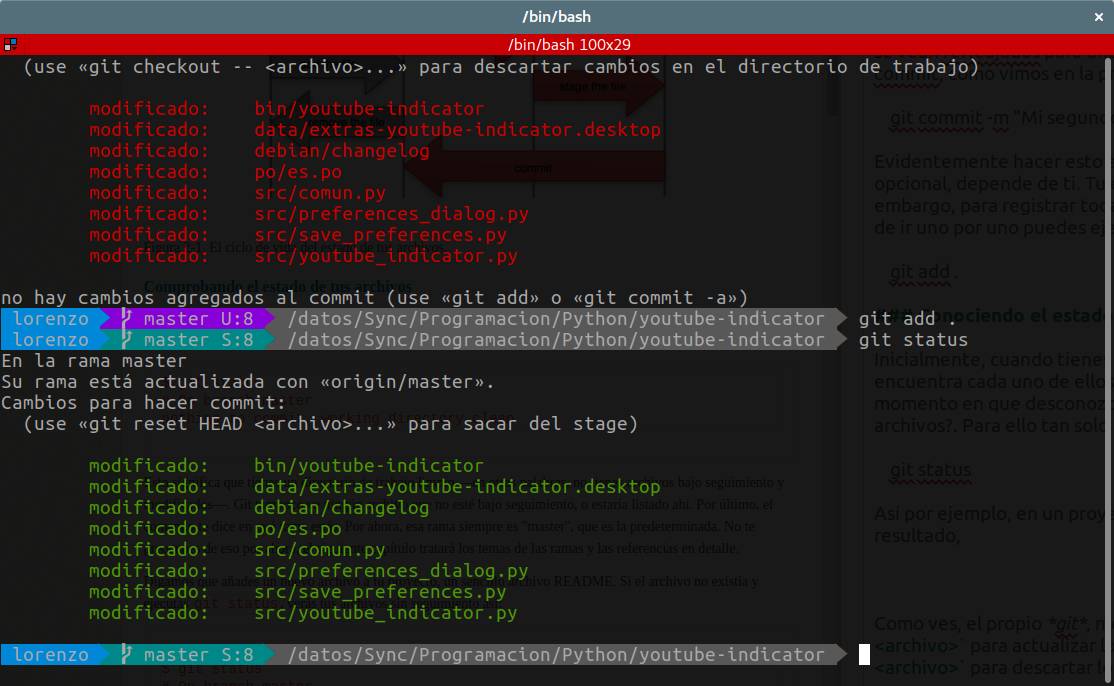
Como puedes ver todos los cambios están registrados en el stage, lo que hemos llamado el estado intermedio. Igual que en el caso anterior, git nos da dos nuevas posibilidades para hacer. Por un lado realizar un commit, o bien sacar uno o varios archivos del stage. Para sacar un archivo del stage, por ejemplo debian/changelog ejecutaremos la siguiente orden:
git reset HEAD debian/changelog
Si volvemos a ver el estado de nuestro repositorio, ejecutando la orden git status ahora el resultado que nos arroja es significativamente distinto. Por un lado, tenemos los archivos sobre los que no hemos hecho nada, y que están preparados para el commit (en color verde), y por otro lado, tenemos el archivo que hemos devuelto a su estado anterior, y que se encuentra en el estado inicial (en color rojo).
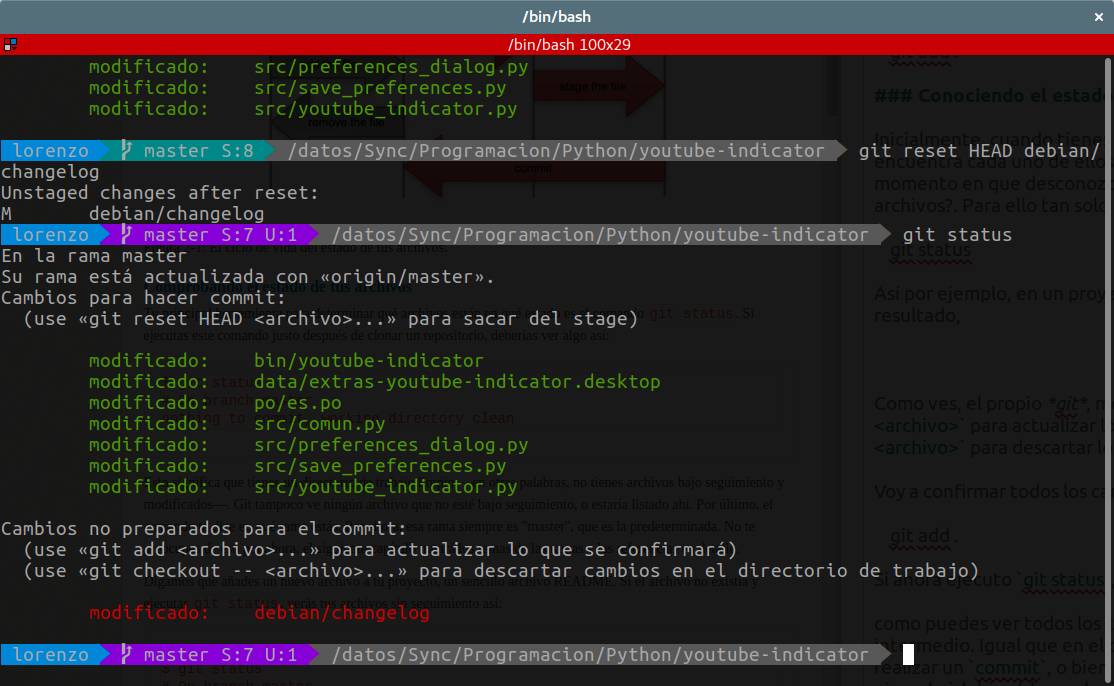
Para este segundo archivo, tenemos dos opciones distintas. O bien registramos los cambios pasandolo al stage y preparándolo para el commit, o bien, lo devolvemos a su estado anterior, ejecutando la orden:
git checkout -- debian/changelog
De esta forma, se desharían los cambios que hayamos realizado sobre el archivo en cuestión.
Voy a registrar los cambios en debian/changelog utilizando git add debian/changelog y posteriormente voy a realizar un commit:
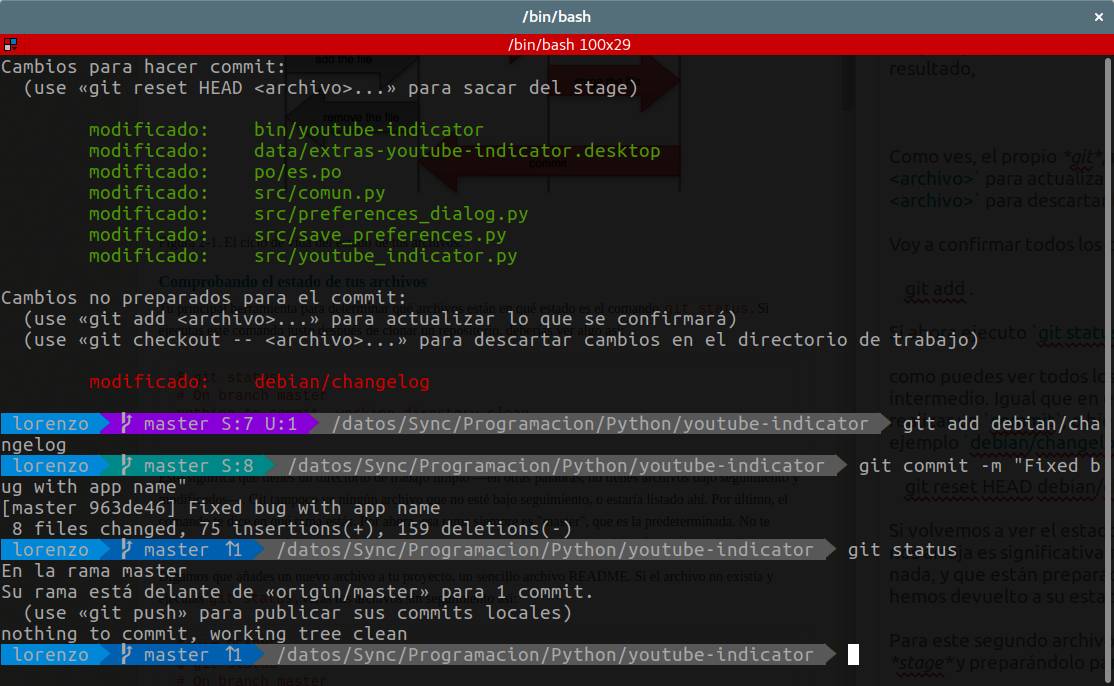
Si te fijas, al realizar el commit, nos da una estadística mínima, en la que se recoge:
- Número de archivos modificados
- Número de líneas añadidas
- Número de líneas borradas
Ahora, al ejecutar la orden git statusnos indica que la rama está preparada para publicar el commit, es decir, para sincronizar nuestro repositorio con el repositorio remoto. Además, nos indica que no hay nada más que hacer.
Al detalle con los cambios diff
Evidentemente, como has podido ver, git status solo nos da una idea de la situación de cada archivo pero nos informa de lo que ha sucedido con él. Para ello es necesario de entrar al detalle. Así por ejemplo, en otro proyecto que llevo entre manos al ejecutar la orden git diff src/nautilus-crusher.pynos arroja el siguiente resultado:
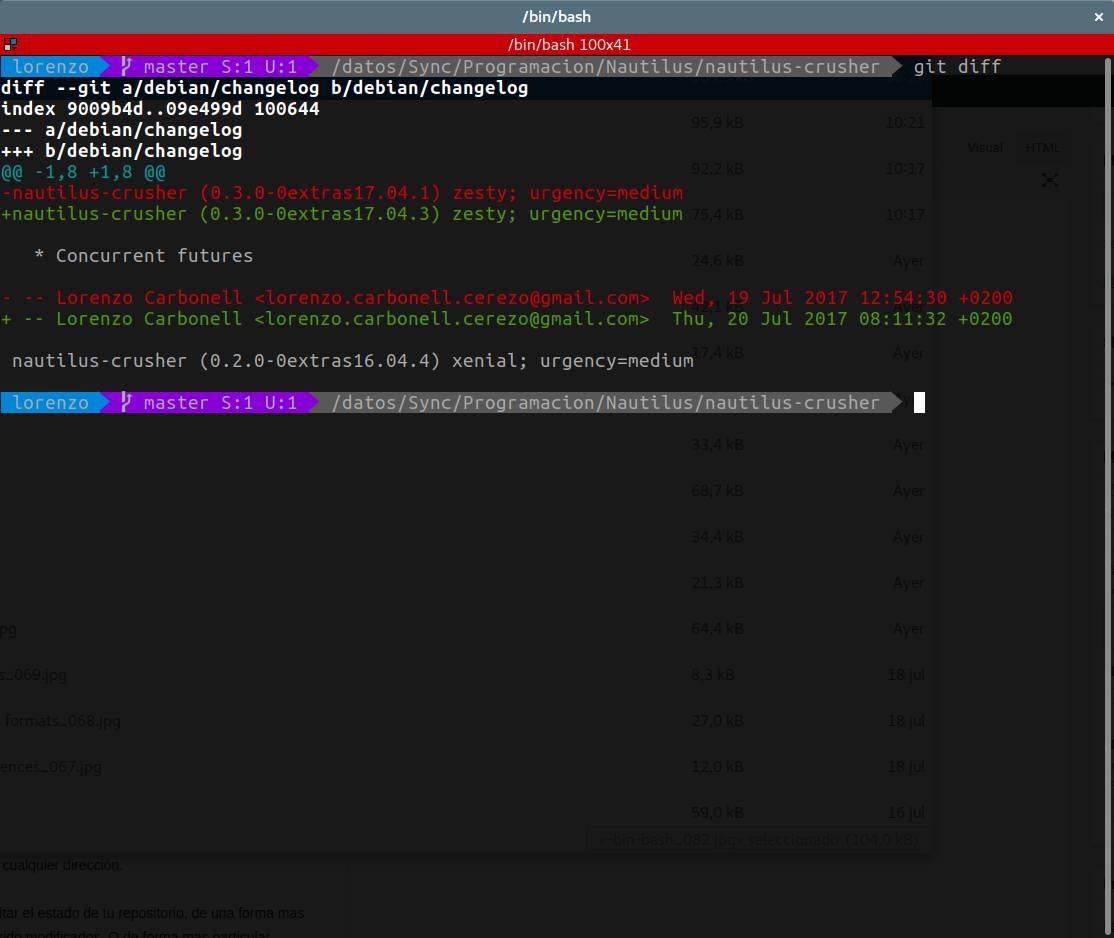
En color rojo, estamos viendo las líneas que se han eliminado, mientras que en color verde, veremos las líneas que se han añadido. Hay que indicar que cuando se modifica una línea se considera como si se hubiera borrado por completo, y se añadiera la línea modificada.
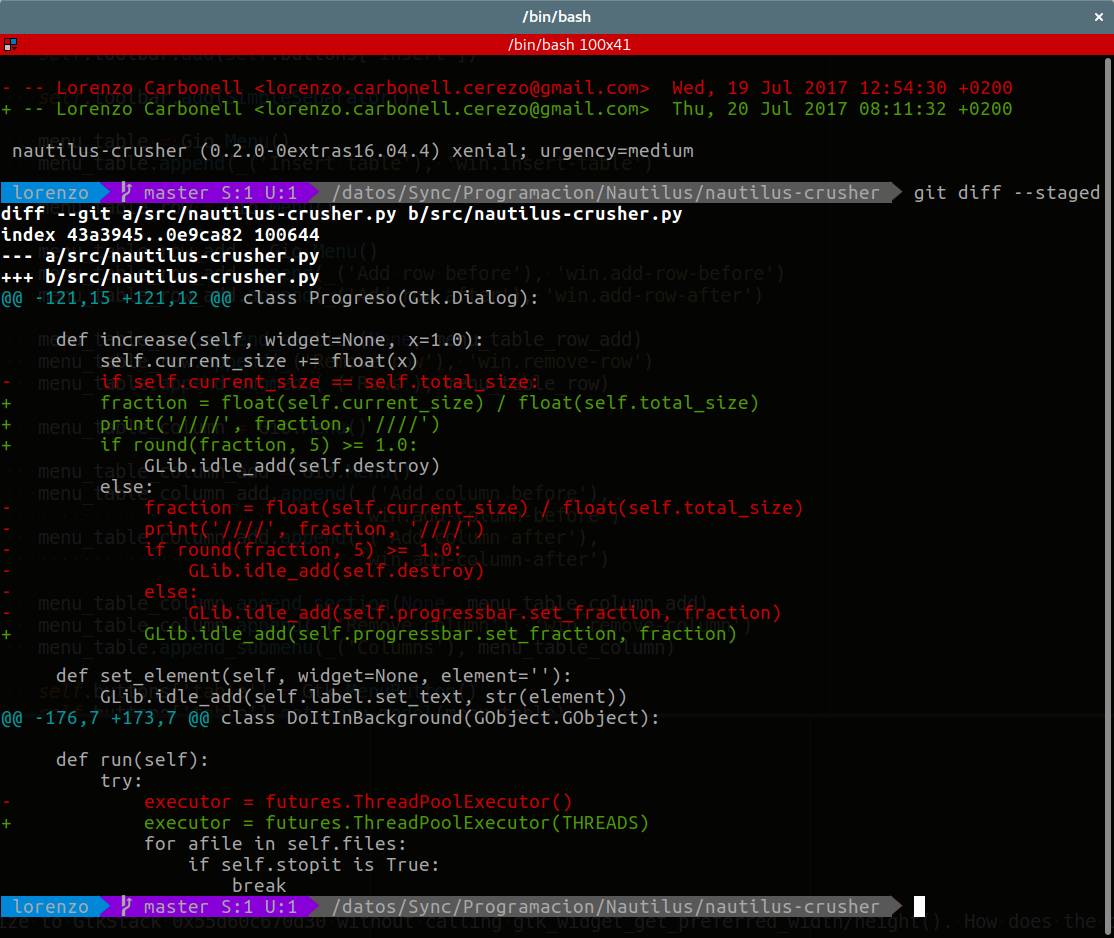
Si ejecutamos git diff sin indicar ningún archivo, nos mostrará todos los cambios ocurridos en nuestro repositorio local. Indicar, que git diffmuestra solo los cambios realizados pero que están pendientes de registrar. Para ver los cambios que están registrados y pendientes de confirmar, debemos ejecutar la orden git diff --cached o git diff --staged, indiferentemente.
Conclusiones
En este artículo has visto como funcionan los repositorios locales, como registrar archivos para llevar un seguimiento de todos los cambios que se van produciendo. Como utilizar los diferentes estados en el repositorio local, y como pasar de uno a otro en cualquier dirección.
Así mismo, también has visto como puedes consultar el estado de tu repositorio, de una forma mas general, viendo únicamente los archivos que han sido modificados. O de forma mas particular, entrando en las entrañas de esos archivos y viendo línea por línea, cuales han sido añadidas o cuales han sido modificadas.
En el siguiente artículo de la serie veremos cómo trabajar con repositorios remotos y algunas utilidades adicionales que nos harán más fácil la vida con git.
Más información,
Imágenes originales modificadas y adaptadas de:
- Cigüeña de Gerald con licencia CC0 Public Domain
- Logo Git con licencia Creative Commons Attribution 3.0 Unported.
")




Muchas gracias por esta serie de tutoriales de Git, estoy haciendo buen uso de ellos.
Parece que omitiste un diagrama después de este párrafo:
«En el siguiente diagrama o esquema vemos todas las posibles transacciones que podemos realizar con un archivo dentro de nuestro repositorio local.»
Por otro lado hablas del uso de «git add .» que parece que tiene diferentes significados según la version de Git (versión 1 ó 2). Yo quizás desaconsejaría su uso. Se puede encontrar información, por ejemplo, en Stack Overflow (https://stackoverflow.com/questions/572549/difference-between-git-add-a-and-git-add)
Saúdos,